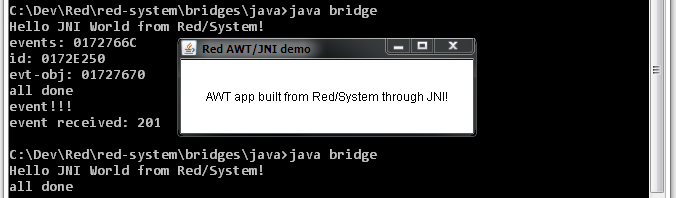
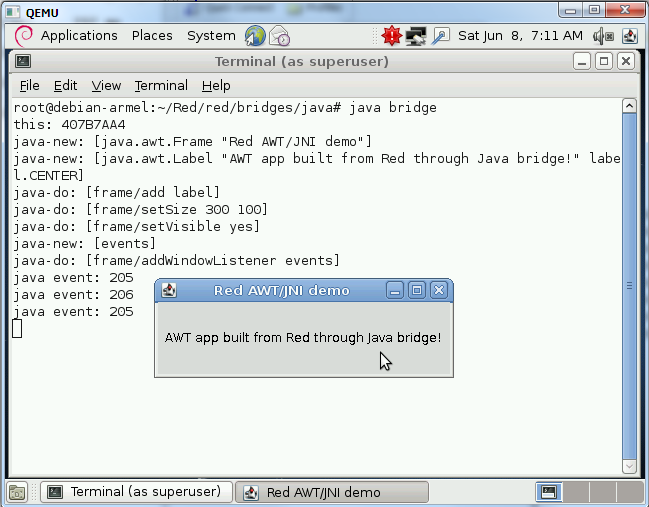
So, in short, what is Parse? It is an embedded DSL (we call them "dialects" in the Rebol world) for parsing input series using grammar rules. The Parse dialect is an enhanced member of the TDPL family. Parse's common usages are for checking, validating, extracting, modifying input data or even implementing embedded and external DSLs.
The parse function call syntax is straightforward:
parse <input> <rules>
<input>: any series value (string, file, block, path, ...)
<rules>: a block! value with valid Parse dialect content
Here are a few examples, even if you don't know Red and Parse dialect, you can still "get" most of them, unlike regexps. You can copy/paste them directly into the Red console.Some simple examples of string or block input validation using grammar rules:
parse "a plane" [["a" | "the"] space "plane"]
parse "the car" [["a" | "the"] space ["plane" | "car"]]
parse "123" ["1" "2" ["4" | "3"]]
parse "abbccc" ["a" 2 "b" 3 "c"]
parse "aaabbb" [copy letters some "a" (n: length? letters) n "b"]
parse [a] ['b | 'a | 'c]
parse [hello nice world] [3 word!]
parse [a a a b b b] [copy words some 'a (n: length? words) n 'b]
How to parse an IPv4 address accurately:
four: charset "01234"
half: charset "012345"
non-zero: charset "123456789"
digit: union non-zero charset "0"
byte: [
"25" half
| "2" four digit
| "1" digit digit
| non-zero digit
| digit
]
ipv4: [byte dot byte dot byte dot byte]
parse "192.168.10.1" ipv4
parse "127.0.0.1" ipv4
parse "99.1234" ipv4
parse "10.12.260.1" ipv4
data: {
ID: 121.34
Version: 1.2.3-5.6
Your IP address is: 85.94.114.88.
NOTE: Your IP Address could be different tomorrow.
}
parse data [some [copy value ipv4 | skip]]
probe value ; will ouput: "85.94.114.88"
A crude, but practical email address validator:
digit: charset "0123456789"
letters: charset [#"a" - #"z" #"A" - #"Z"]
special: charset "-"
chars: union union letters special digit
word: [some chars]
host: [word]
domain: [word some [dot word]]
email: [host "@" domain]
parse "john@doe.com" email
parse "n00b@lost.island.org" email
parse "h4x0r-l33t@domain.net" email
Validating math expressions in string form (from Rebol/Core manual):
expr: [term ["+" | "-"] expr | term]
term: [factor ["*" | "/"] term | factor]
factor: [primary "**" factor | primary]
primary: [some digit | "(" expr ")"]
digit: charset "0123456789"
parse "1+2*(3-2)/4" expr ; will return true
parse "1-(3/)+2" expr ; will return false
Creating a simple parser for a subset of HTML:
html: {
<html>
<head><title>Test</title></head>
<body><div><u>Hello</u> <b>World</b></div></body>
</html>
}
ws: charset reduce [space tab cr lf]
parse html tags: [
collect [any [
ws
| "</" thru ">" break
| "<" copy name to ">" skip keep (load name) opt tags
| keep to "<"
]]
]
; will produce the following tree of blocks as output of parse:
[
html [
head [
title ["Test"]
]
body [
div [
u ["Hello"]
b ["World"]
]
]
]
]
The Parse dialect
Parse's core principles are:
- Advance input series by matching grammar rules until top-level rule failure (returning false) or input exhaustion (returning true). (*)
- Ordered choices (e.g. in ["a" | "ab"] rule, the second one will never succeed).
- Rules composability (unlimited).
- Limited backtracking: only input and rules positions are backtracked, other changes remain.
- Two modes: string-parsing (for example: external DSL) or block-parsing (for example: embedded DSL).
The Parse rules can be made from:
- keyword : a dialect reserved word (see the tables below).
- word : word will be evaluated and its value used as a rule.
- word: : set the word to the current input position.
- :word : resume input at the position referenced by the word.
- integer value : specify an iterated rule with a fixed number or a range of iterations.
- value : match the input to a value
- | : backtrack and match next alternate rule
- [rules] : a block of sub-rules
- (expression) : escape the Parse dialect, evaluate a Red expression and return to the Parse dialect.
The following keywords are currently available in Red's Parse implementation. They can be composed together freely.
Matching
| ahead rule | : look-ahead rule, match the rule, but do not advance input. |
| end | : return success if current input position is at end. |
| none | : always return success (catch-all rule). |
| not rule | : invert the result of the sub-rule. |
| opt rule | : look-ahead rule, optionally match the rule. |
| quote value | : match next value literally (for dialect escaping needs). |
| skip | : advance the input by one element (a character or a value). |
| thru rule | : advance input until rule matches, input is set past the match. |
| to rule | : advance input until rule matches, input is set at head of the match. |
Control flow
| break | : break out of a matching loop, returning success. |
| if (expr) | : evaluate the Red expression, if false or none, fail and backtrack. |
| into rule | : switch input to matched series (string or block) and parse it with rule. |
| fail | : force current rule to fail and backtrack. |
| then | : regardless of failure or success of what follows, skip the next alternate rule. |
| reject | : break out of a matching loop, returning failure. |
Iteration
| any rule | : repeat rule zero or more times until failure or if input does not advance. |
| some rule | : repeat rule one or more times until failure or if input does not advance. |
| while rule | : repeat rule zero or more times until failure regardless of input advancing. |
Extraction
| collect [rule] | : return a block of collected values from the matched rule. |
| collect set word [rule] | : collect values from the matched rule, in a block and set the word to it. |
| collect into word [rule] | : collect values from the matched rule and insert them in the block referred by word. |
| copy word rule | : set the word to a copy of the matched input. |
| keep rule | : append a copy of the matched input to the collecting block. |
| keep (expr) | : append the last value from the Red expression to the collecting block. |
| set word rule | : set the word to the first value of the matched input. |
Modification
| insert only value | : insert[/only] a value at the current input position and advance input after the value. |
| remove rule | : remove the matched input. |
The core principles mention two modes for parsing. This is necessary in Red (as in Rebol) because of the two basic series datatypes we have: string! and block!. The string! datatype is currently an array of Unicode codepoints (Red will support an array of characters in a future version) while the block! datatype is an array of arbitrary Red values (including other blocks).
In practice, this results in some minor differences in Parse dialect usage. For example, it is possible to define arbitrary sets of characters using the new bitset! datatype, which are useful only for string! parsing in order to match with a large number of characters in one time. Here is an example using only bitsets matching and iterators:
letter: charset [#"a" - #"z"]
digit: charset "0123456789"
parse "hello 123 world" [5 letter space 3 digit space some letter]
The Bitset! datatype
A bitset value is an array of bits that is used to store boolean values. In the context of Parse, bitsets are very useful to represent arbitrary sets of characters across the whole Unicode range, that can be matched against an input character, in a single operation. As bitset! is introduced in this 0.4.1 release, it is worth having an overview of the features supported. Basically, it is on par with Rebol3 bitset! implementation.
In order to create a bitset, you need to provide one or several characters as base specification. They can be provided in different forms: codepoint integer values, char! values, string! values, a range or a group of previous elements. The creation of a new bitset is done using the following syntax:
make bitset! <spec>
<spec>: char!, integer!, string! or block!
For example:
; create an empty bitset with places at least for 50 bits
make bitset! 50
; create a bitset with bit 65 set
make bitset! #"A"
; create a bitset with bits 104 and 105 set
make bitset! "hi"
; create and set bits using different values representations
make bitset! [120 "hello" #"A"]
; create a bitset using ranges of values
make bitset! [#"0" - #"9" #"a" - #"z"]
Ranges are defined using two values (char! or integer! allowed) separate by a dash word.Bitsets are auto-sized to fit the specification value(s) provided. The size is rounded to the upper byte bound.
A shortcut charset function is also provided for practical usage, so you can write:
charset "ABCDEF"
charset [120 "hello" #"A"]
charset [#"0" - #"9" #"a" - #"z"]
For reading and writing single bits, the path notation is the simplest way to go:
bs: charset [#"a" - #"z"]
bs/97 ; will return true
bs/40 ; will return false
bs/97: false
bs/97 ; will return false
(Note: bitset indexing is zero-based.)Additionally, the following actions are supported by bitset! datatype:
pick, poke, find, insert, append, copy, remove, clear, length?, mold, form
See the Rebol3 bitset documentation for more info about usage of these actions.
In order to cope with the wide range of Unicode characters, bits outside of the bitsets are treated as virtual bits, so they can be tested and set without errors, the bitset size will auto-expand according to the needs. But that is still not enough to deal with big ranges, like for example a bitset for all Unicode characters except digits. For such cases, it is possible to define a complemented bitset that represents the complement range of the specified bits. This makes possible to have large bitsets while using only a tiny memory portion.
Complemented bitsets are created the same way as normal bitsets, but they need to start with the not word and always use a block! for their specification:
; all characters except digits
charset [not "0123456789"]
; all characters but hexadecimal symbols
charset [not "ABCDEF" #"0" - #"9"]
; all characters except whitespaces
charset reduce ['not space tab cr lf]
Set operations are also possible, but only union is currently implemented in Red (it is the most used anyway for bitsets). With union, you can merge two bitsets together to form a new one, which is very useful in practice:
digit: charset "0123456789"
lower: charset [#"a" - #"z"]
upper: charset [#"A" - #"Z"]
letters: union lower upper
hexa: union upper digit
alphanum: union letters digit
Parse implementation
Parse dialect has been implemented as a FSM which differs from the Rebol3 implementation that relies on recursive function calls. The FSM approach makes possible several interesting features, like the ability to stop the parsing and resume it later, or even serialize the parsing state, send it remotely and reload it to continue the parsing. Such features could now be implemented with minimal efforts.
Red Parse implementation is about 1300 lines of Red/System code, with a significant part of it spent on optimized iteration loops for common cases. About 770 unit tests have been hand-written to cover the basic Parse features.
The current Parse runs as an interpreter, which is fast enough for most use-cases you will have. For cases where maximum performance is required, work has started on a Parse static compiler to soon provide the fastest possible speed to Parse-intensive Red apps. The generated code is pure Red/System code and should be about a magnitude faster on average than the interpreted version. When Red will be self-hosted, a Parse JIT compiler will be provided to deal with the cases that the static compiler cannot process.
As Red gets more features, Parse will continue to be improved to take advantage of them. Among other future improvements, binary! parsing will be added as soon as binary! datatype is available, and stream parsing will be possible when port! datatype will be there.
The Red Parse also exposes a public event-oriented API in form of an optional callback function that can be passed to parse using the /trace refinement.
parse/trace <input> <rules> <callback>
<callback> specification:
func [
event [word!] ; Trace events
match? [logic!] ; Result of last matching operation
rule [block!] ; Current rule at current position
input [series!] ; Input series at next position to match
stack [block!] ; Internal parse rules stack
return: [logic!] ; TRUE: continue parsing, FALSE: exit
]
Events list:
- push : once a rule or block has been pushed on stack
- pop : before a rule or block is popped from stack
- fetch : before a new rule is fetched
- match : after a value matching occurs
- iterate : after a new iteration pass begins (ANY, SOME, ...)
- paren : after a paren expression was evaluated
- end : after end of input has been reached
This API will be extended in the future to get more fine-grained events. This API could be used to provide Parse with tracing, stats, debugging, ... Let's see what Red users will come up with! ;-)A default callback has been implemented for tracing purposes. It can be accessed using the handy parse-trace function wrapper:
parse-trace <input> <rules>
You can try it with simple parsing rules to see the resulting output.
What about DSL support?
Parse is a powerful tool for implementing DSL parsers (both embedded and externals), thanks to its ability to inline Red expressions directly into the rules, allowing to easily link the DSL syntax with its corresponding semantics. To illustrate that, here is a simple interpreter for a famous obfuscated language, written using Parse:
bf: function [prog [string!]][
size: 30000
cells: make string! size
append/dup cells null size
parse prog [
some [
">" (cells: next cells)
| "<" (cells: back cells)
| "+" (cells/1: cells/1 + 1)
| "-" (cells/1: cells/1 - 1)
| "." (prin cells/1)
| "," (cells/1: first input "")
| "[" [if (cells/1 = null) thru "]" | none]
| "]" [
pos: if (cells/1 <> null)
(pos: find/reverse pos #"[") :pos
| none
]
| skip
]
]
]
; This code will print a Hello World! message
bf {
++++++++++[>+++++++>++++++++++>+++>+<<<<-]>++.>+.+++++++..+++.
>++.<<+++++++++++++++.>.+++.------.--------.>+.>.
}
; This one will print a famous quote
bf {
++++++++[>+>++>+++>++++>+++++>++++++>+++++++>++++++++>
+++++++++>++++++++++>+++++++++++>++++++++++++>++++++++
+++++>++++++++++++++>+++++++++++++++>++++++++++++++++<
<<<<<<<<<<<<<<<-]>>>>>>>>>>>----.++++<<<<<<<<<<<>>>>>>>
>>>>>>.<<<<<<<<<<<<<>>>>>>>>>>>>>---.+++<<<<<<<<<<<<<>>
>>>>>>>>>>>>++.--<<<<<<<<<<<<<<>>>>>>>>>>>>>---.+++<<<<
<<<<<<<<<>>>>.<<<<>>>>>>>>>>>>>+.-<<<<<<<<<<<<<>>>>>>>>
>>>>>>+++.---<<<<<<<<<<<<<<>>>>.<<<<>>>>>>>>>>>>>>--.++
<<<<<<<<<<<<<<>>>>>>>>>>>>>>-.+<<<<<<<<<<<<<<>>>>.<<<<>
>>>>>>>>>>>>>+++.---<<<<<<<<<<<<<<>>>>>>>>>>>>>>.<<<<<<
<<<<<<<<>>>>>>>>>>>>>>-.+<<<<<<<<<<<<<<>>>>>>>>>>>>>>-.
+<<<<<<<<<<<<<<>>>>>>>>>>>>>>--.++<<<<<<<<<<<<<<>>>>+.-
<<<<.
}
Note: this implementation is limited to one-level of "[...]" nesting to keep it as short as possible. A complete, but a bit more longer and complex implementation using Parse only, is availaible here.So, such approach works incredibly well for small DSLs. For more sophisticated ones, Parse still works fine, but it might be less helpful as the DSL semantics get more complex. Implementing an interpreter or compiler for a more advanced DSL is not a trivial task for most users. Red will address that in the future by providing a meta-DSL wrapper on top of Parse, exposing a higher-level API to build more sophisticated DSL by abstracting away core parts of an interpreter or compiler. A DSL for building other DSLs is not a crazy idea, it already exists in a very powerful form as the Rascal language for example. What Red will provide, will be just one step in that direction, but nothing as sophisticated (and complex) as Rascal.
Other changes in this release
Just to mention other changes in this release, now that we got rid of the 800 pound gorilla in the room. This release brings a significant number of bug fixes, both for Red and Red/System. Also, thanks to qtxie, the ELF file emitter is now on par with the other ones when producing shared libraries.
Thanks to all the people involved in helping for this big release, including design fixes and improvements, testing, bug reporting and test writing.
Enjoy! :-)